
When you look at a blog or a new site, your mind kicks into high gear and begins to parse all the pieces and parts of a site that you are looking at. Then it stores into memory the things that interest you. Our minds are so good at doing this that we can take this piece of information from a website that we have not seen before which might follow different ways of displaying data. But for a moment let’s do a little experiment:
Imagine before you consumed anything from a web page you had to understand all of the relationships on the web page already had in advance. For ex: You would require a perfect understanding of a relationship between the writer and the article or a perfect understanding of the relationship of the article to the advertisement. If you didn’t understand that relationship between them and others, your brain will literally say no to taking in the information. This is a weird data experiment.
But this is literally what happens when we store data in a relational database. We have to know upfront what the structure or schema of the data is before we write data into it and this prerequisite is one of the primary reasons why NoSQL and Hadoop came about.
NoSQL represents a really broad category of databases which allows large quantities of semi-structured and unstructured data to be stored and managed. Now additionally, they are designed to handle a high level of reads and writes while scaling horizontally.
For Ex: if you take an honest assessment at your ability to parse a database or a web page you will find that your mind actually needs a quite a bit of context before it can make any opinion about what they are looking at. Pick out a less common data visualization and you will come to a realization that what you are understanding about what is going on is highly reliant on your ability to master your previously used context or experience.
Now compare this to browsing a favorite website or web page. You don’t fumble around trying to figure out how to use it. Instead, you instantly go ahead into data processing and storage mode. So what we have learned about this is that we can gain a confidence when we are reading about a record to which we can apply a structure to the information we are storing.
However, it takes a little more time to upfront to define those categories and structures on our own minds, that turns out that the databases on the same way. Relational databases take this to one extreme being highly structured and Hadoop takes it to another being highly unstructured.
Now, NoSQL, on the other hand, sits in this Goldie lock zone. They allow you to apply a structure to the stored data even though there is not a logical category for it. So let’s see a couple of examples now as compared to SQL:
Imagine that you are storing information in a Product Catalog using Relational Database and you receive new sills from your regular suppliers. Now in Relational Databases, you would have your data model ready to consume data from your suppliers as data would come in. You could need to confirm that the data fit the data model but it didn’t, you would need to make a decision either you would have to transfer it to the data model or change the model to fit the new data element.
Now in most of the cases organizations have started to transform the data that takes a serious amount of discipline and skills on regular basis from their manufacturers or suppliers.
Now, imagine that you have a NoSQL database on the backend. You still would have data transformations which you could apply tagging to the data but if data come in which you have not previously categorized you would still be able to land in the NoSQL database. You can then see the data later and decide if it takes a common enough category to create a semi-structured tag for it. Which would enable it to be processed quickly for the future read and write.
There are different types of NoSQL databases with a lot of different kinds of structured advantages for Ex: If you have a column store which stores columns and it can expand to millions of columns to which it can store. Other examples are Graph databases, Hybrid Cache Store.
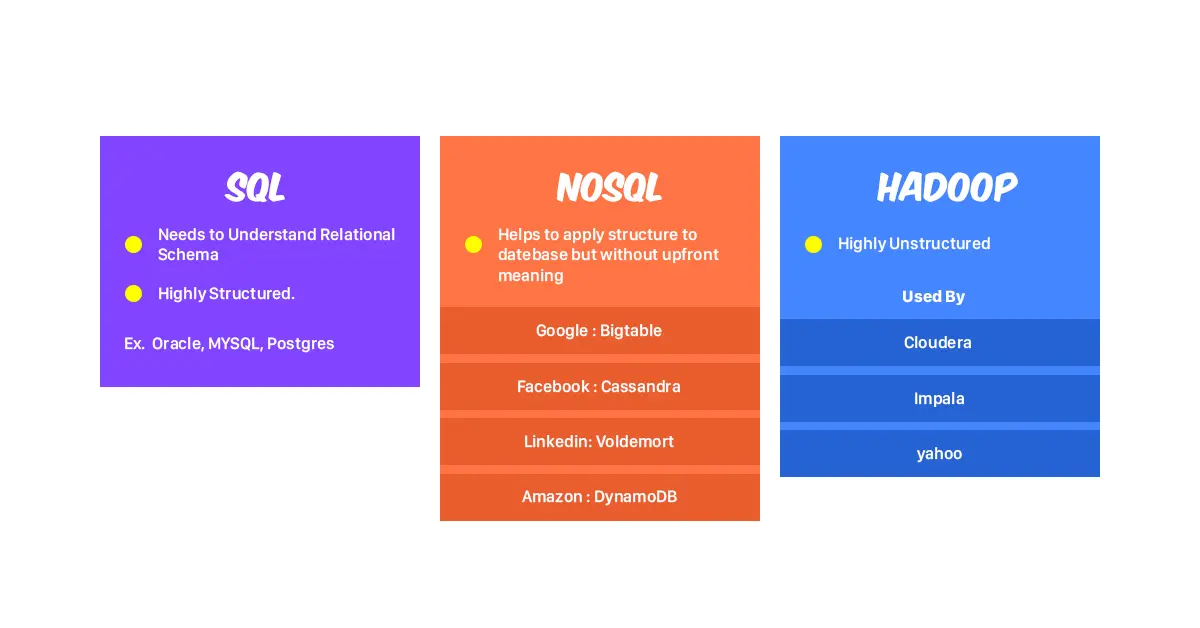
We no longer live in a world of one size fits all data, there are tangible benefits in taking processes that previously were forced into a relational database and considering the use of NoSQL and Hadoop.
You must log in to post a comment.