
We are continuing with our core Linux Architecture. In the last article, we were talking about memory access schemes Process Management and most predominant of them is Virtual Memory. Today we are going to discuss Virtual Memory.
Virtual Memory:-
It is a memory access scheme and it is implemented using hardware and software. What is the idea behind it? It maps Virtual Addresses. In other words, memory addresses used by a program to physical addresses on the hardware and from process’ view virtual address space is a continuous chunk. From the program’s point of view, it has all this memory allocated to just one blog.
Let’s see why that is useful? The following diagram will help us to understand how does this virtual or physical translation occur?
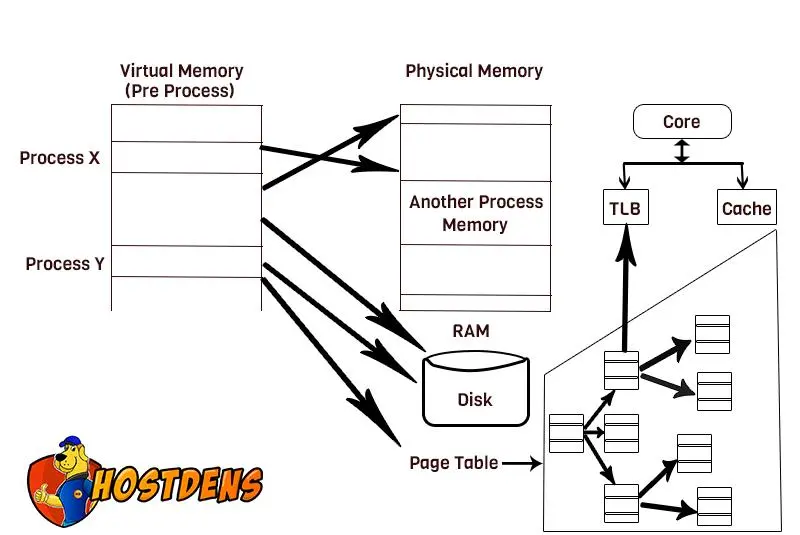
How virtual memory per process works:- All the virtual addresses in a virtual memory that are available to a program to store its things in RAM, all looks like a continuous portion of memory and those through this virtual memory access scheme are mapped to particular parts in physical memory or locations. Each of these is locations and you can see that through this memory access scheme multiple processes can share the physical memory although it just looks like one continuous space for the program.
It is very important, as we talked about it in the last article that is why do we need a memory management? Like a scheme and we talked about the downsides and the downsides being what an overload that will be to the developers to have to look at all of these spaces and check whether somebody else or another program utilizing it? What if there is a namespace collision? What is it if different people are trying to access the same piece of memory at the same time. That’s just huge nightmare. Therefore we need the virtual memory.
Memory Management Unit (MMU):- It resides inside the CPU. This has to deal with Virtual memory essentially with all this virtual memory stuff. So this MMU is pretty much implemented inside every single virtual memory system.
In general, Kernel maintains a page table which you already know that. This page table maps a process’ virtual page address to a physical address. It is just a mapping file. Each page table has a single page table entry(PTE). Each PTE has a “PAGE_USER” bit that specifies if a page can or cannot be accessed from the userspace. So this essentially what we were talking about when we were discussing about privileges that are what is code and what CPU instructions access?
It is important to note that Kernel creates pages and a page is the smallest unit of memory. In a virtual memory operating system. The foundation of sandboxing is a “PAGE_USER” bit. It is very important. Also, remember when we were discussing why Ring 0 and 3 were utilized because the page table entry only has 2 levels of permissions and that is why there are only 2 corresponding rings in Linux.
Translation Lookaside Buffer (TLB):
– It is housed in the MMU. It caches recently used PTE. Once PTE is cached the page can be accessed.
Do the actual pages need to be loaded into memory at all the times? – No! In general, we don’t need all the pages loaded at once. So that’s where the on-demand paging comes into action.
Demand Paging:-
In this, the Kernel generally loads and allocates pages as a process needs them. For ex: – When a new process is executed :
- Kernel loads the beginning of the process’ instruction code into pages.
- A kernel may allocate some working – memory pages to the new process.
- As the process runs there might be a point where it tries to access a page via a virtual address, that isn’t physically loaded in main memory.
- A page is triggered by the MMU.
- The kernel takes over.
- Kernel loads the necessary pages into memory and gives control back to the process.
- What if all processes RAM needs are greater than RAM? That is where we need RAM.
Paging – Kernel moves pages from memory to the disk’s swap space to expand the process’ memory.
Also handles the disk to memory process. As shown in the diagram, the process doesn’t directly access the disk. The page is loaded into the RAM from the swap space first and then it is utilized by the process.
so do we need paging if system RAM is greater than all processes RAM needs? Do we need paging?
The answer is: Yes! we need it. A significant number of pages referenced by the process early in its life may only be used for utilized for initialization and they never are used again. It is better to swap out these pages to the disk before RAM demand grows. This is called housekeeping and as we have seen paging can occur when a page fault is triggered by the MMU.
Page Fault Types: –
- Minor Page Faults:-
It occurs when the desired page is in main memory but the MMU doesn’t know where it is. It can occur if the MMU doesn’t have enough space to store all of the PTEs.
Solution – Kernel informs the MMU about the page’s location and the process will continue. Not a big deal unless maximum performance is needed.
- Major Page Faults: –
It occurs when the desired page is not in main memory at all. A kernel must load it from disk which can lead to thrashing.
Visit – Hostdens
You must log in to post a comment.